TensorFlow官網首頁的範例只有短短的10多行,但是每一行指令及參數都內含許多玄機,雖然我們在前面已回答及實驗許多核心問題,但還是有一些疑問待探討,以下就來作一些補充說明。

除了前面的討論,還是有一些問題:
1.要準備多少訓練資料才夠?
2.要訓練幾個執行週期(Epoch)才夠?
3.Dense輸出的神經元個數該設定幾個? Dense要幾層?
4.如何保證不會錯判類別? 例如停車收費,業者要求『車牌號碼寧可辨識不出來,也不要辨識錯誤』,因為辨識不出來,可以人工補救,辨識錯誤則會引起客訴,造成業者金錢損失及聲譽受損,許多金融產業或工業都會有類似的要求。
以上幾乎都沒有標準答案,只有一些指引。
要準備多少訓練資料,才可以保證達到期望的準確度? 很簡單,當然是越多越好,以手寫阿拉伯數字辨識為例,如果可以蒐集全世界每一個人的寫法,那麼訓練出來的模型,必然會令人滿意,但是,現實上是不可行的,必須考慮時間、人力及經費的限制,而有所取捨,另外,辨識的複雜度也是考量的因素,例如MNIST與CIFAR-10,如下圖,後者背景複雜,辨識難度高很多,當然要更多的訓練資料,例如,ILSVRC影像辨識大賽的模型就是利用ImageNet 100多萬張的圖片作為訓練資料,加上更複雜的神經網路、更多的訓練週期,準確率可高達98%以上。

圖一. MNIST vs CIFAR-10
但是,很多的訓練資料會引發另一個問題,一次載入所有的訓練資料,記憶體會爆掉,因此,TensorFlow提供Dataset,一次只讀取一批(batch)資料進行訓練,完成後再讀取下一批資料訓練,這樣才能節省記憶體,詳閱『同時搞定TensorFlow、PyTorch (三) :資料前置處理』,PyTorch則使用Dataset/DataLoader搭配,兩者都是使用Iterator資料結構,另外,可以使用Prefetching、Cache、平行處理...等設定,加速訓練,詳閱『Better performance with the tf.data API』。
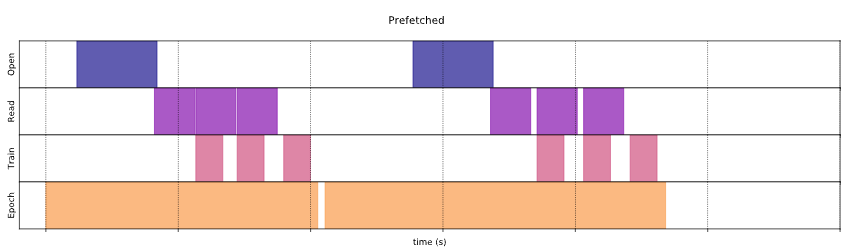
圖二. Prefetching可在訓練一批資料時,同時讀取下一批資料訓練,充分利用CPU/GPU及硬碟資源
通常我們會訓練較多的執行週期,確保模型的準確度,但是這樣做有兩個問題:
TensorFlow/Keras有提供EarlyStopping callback,可設定條件提早結束訓練,例如訓練多個執行週期都沒有顯著進展,即可停止訓練,不過這種方式並不保證面對測試資料或新資料時,模型會有高準確率,還是應以後續的測試評分為準,例如手寫阿拉伯數字辨識,官網範例準確率高達97%,但實際使用滑鼠書寫測試,準確率並不高。
理論上越多神經元個數或越多層Dense,都會產生更多的迴歸線,模型會越複雜,準確率會提升,但是,到底要設定多少,並沒有定論,因為,每個計畫收集到的訓練資料筆數均不相同,資料內容也五花八門,目前並沒有適當的指引,只有靠經驗與實驗判斷。
前面討論過,最後一層Dense輸出可經由Softmax activation function轉換為機率格式,但其預測值只是排序(Ranking),並非可信度,要避免錯判類別,可另外再考慮以相似度(Cosine similarity)或其他方式驗證,以降低錯判的機率。
前面僅對一般的神經網路(Vainilla neural network)進行討論,以下再針對其他的神經網路發展的動機及關聯,進行簡單的說明。
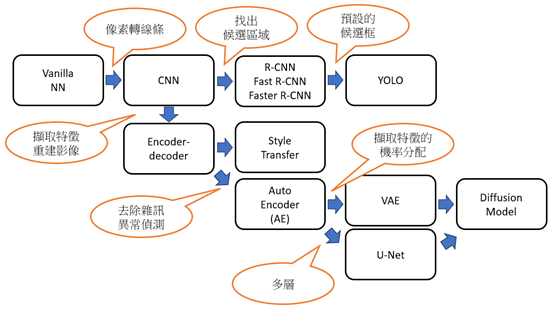

另外,有兩個技巧值得關注:
資料增補(Data Augmentation):手寫阿拉伯數字辨識實測不準確的原因還有一個,MNIST是收集美國郵局員工及高中生手寫的圖像,與台灣人寫法有些許差異,另外,當初是使用筆書寫,再掃描存檔,與我們以滑鼠書寫也不相同,因此,我們可以運用Data Augmentation的影像處理技術,產生各種偏斜、大小不同的訓練資料,使訓練出來的模型更強韌,可以接受各種書寫風格,這種由電腦生成訓練資料的技術也可應用到語音、文字上,可大量減少標記資料的人力。
圖四. 資料增補(Data Augmentation)
轉移學習(Transfer Learning):將預先訓練好的模型(Pre-trained Models)應用到其他類型物件的辨識,例如辨識ImageNet提供1000種事物的模型,接上自己的input及辨識層,即可辨識1000種事物以外的東西,大語言模型(LLM)也可利用轉移學習,調校(Fine tuning)特定任務,例如情緒分析、翻譯...等。
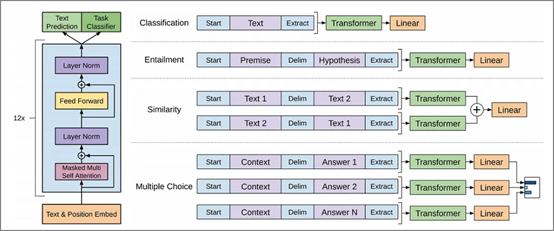
圖五. GPT Model與微調任務(Fine-tuning tasks),圖片來源:ChatGPT Architecture Explained
YOLO至今已經發展至第12版,其中也有中研院的貢獻(v4、v7、v9),以Ultralytics提供的解決方案最為完整,光基本功能就包括:
延伸的解決方案更包括:
自然語言處理(NLP)概分兩個方向:
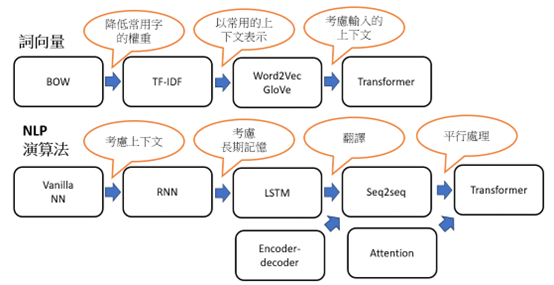
詞向量發展趨勢:

演算法發展趨勢:
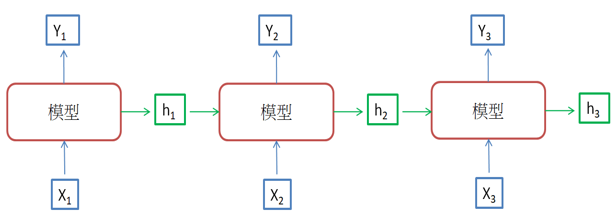
以上的神經網路模型不管多複雜,都是以梯度下降法求解,因此,筆者認為要敲開深度學習的大門,必須要徹底理解梯度下降法,後續才能快速學會各種演算法及發展趨勢,更多的範例及應用,可參閱拙著的『深度學習最佳入門與專題實戰』一書。
徹底理解神經網路的核心 -- 梯度下降法 (1)
徹底理解神經網路的核心 -- 梯度下降法 (2)
徹底理解神經網路的核心 -- 梯度下降法 (3)
徹底理解神經網路的核心 -- 梯度下降法 (4)
徹底理解神經網路的核心 -- 梯度下降法的應用 (5)
梯度下降法(6) -- 學習率動態調整
梯度下降法(7) -- 優化器(Optimizer)
梯度下降法(8) -- Activation Function
梯度下降法(9) -- 損失函數
梯度下降法(10) -- 總結
 I code so I am
I code so I am
